I am an assistant professor at the Graduate School of Culture Technology (GSCT), KAIST, where I focus on developing machines that bridge the physical and digital worlds to enrich musical creativity.
I have been working on music technology, physics-based computer simulation, and acoustic transducer design, at the KAIST ![]()
Musical Acoustics and Transducer Instrument Engineering Laboratory.
Prior to the current position I was a postdoctoral associate at MIT RLE, Laboratory for Audio, Music, and Acoustics.
I received Ph.D. (2024) from Seoul National University (SNU), following a B.Sc. (2019) from Pohang University of Science and Technology (POSTECH).
| Work with MFA was featured in MIT News | March 5, 2026 |
| Will start as an Assistant Professor at KAIST in Fall 2026 | February 20, 2026 |
| Recognized as a NeurIPS 2025 Top Reviewer | October 17, 2025 |
| Joined MIT as a postdoc | July 1, 2025 |
| [view more] |
|
Cambridge, MA, 2025 - 2026 MIT, Postdoctoral Associate |
|
Seoul, KR, 2025 Gaudio Lab, AI Scientist |
|
Redmond, WA, 2024 Meta, Research Scientist Intern |
|
Seoul, KR, 2021,2023 Supertone, Research Scientist Intern |
|
Seoul National University (SNU)
|
|
Pohang University of Science and Technology (POSTECH) |
[Google Scholar]
[h5-index:
Engineering & Computer Science /
Artificial Intelligence /
Acoustics & Sound
]
Selected publications are highlighted.
| 7. |
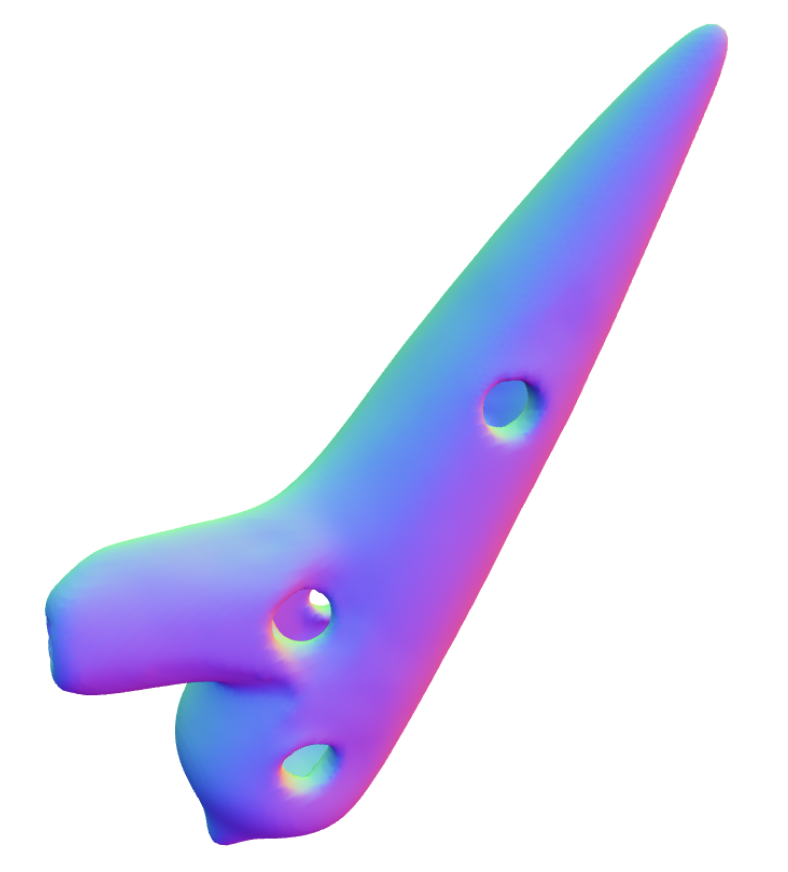
 Differentiable Modal Synthesis for Physical Modeling of Planar String Sound and Motion Simulation
[TL;DR] [poster] [openreview]
Differentiable Modal Synthesis for Physical Modeling of Planar String Sound and Motion Simulation
[TL;DR] [poster] [openreview] Jin Woo Lee, Jaehyun Park, Min Jun Choi, and Kyogu Lee NeurIPS 2024 |
| 8. |
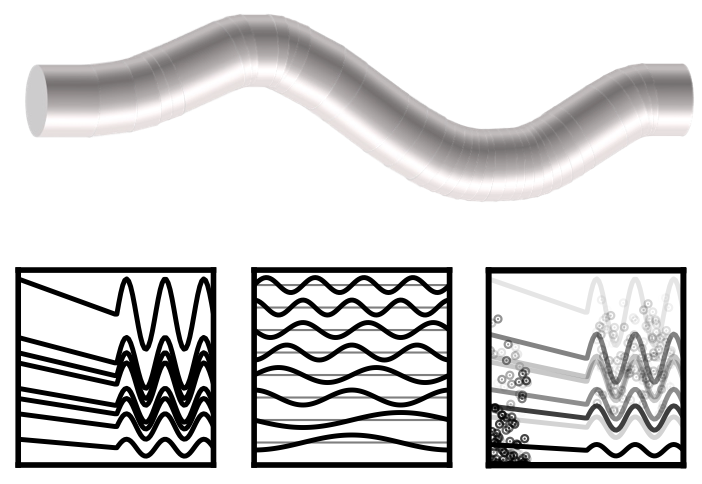
 Inverse Nonlinearity Compensation of Hyperelastic Deformation in Dielectric Elastomer for Acoustic Actuation
[TL;DR]
Inverse Nonlinearity Compensation of Hyperelastic Deformation in Dielectric Elastomer for Acoustic Actuation
[TL;DR]Jin Woo Lee, Gwangseok An, Jeong-Yun Sun, and Kyogu Lee IEEE Access 2024 |
| 9. |
 String Sound Synthesizer on GPU-accelerated Finite Difference Scheme
[TL;DR] [code] [demo] [poster]
String Sound Synthesizer on GPU-accelerated Finite Difference Scheme
[TL;DR] [code] [demo] [poster] Jin Woo Lee, Min Jun Choi, and Kyogu Lee IEEE ICASSP 2024 |
| 10. |
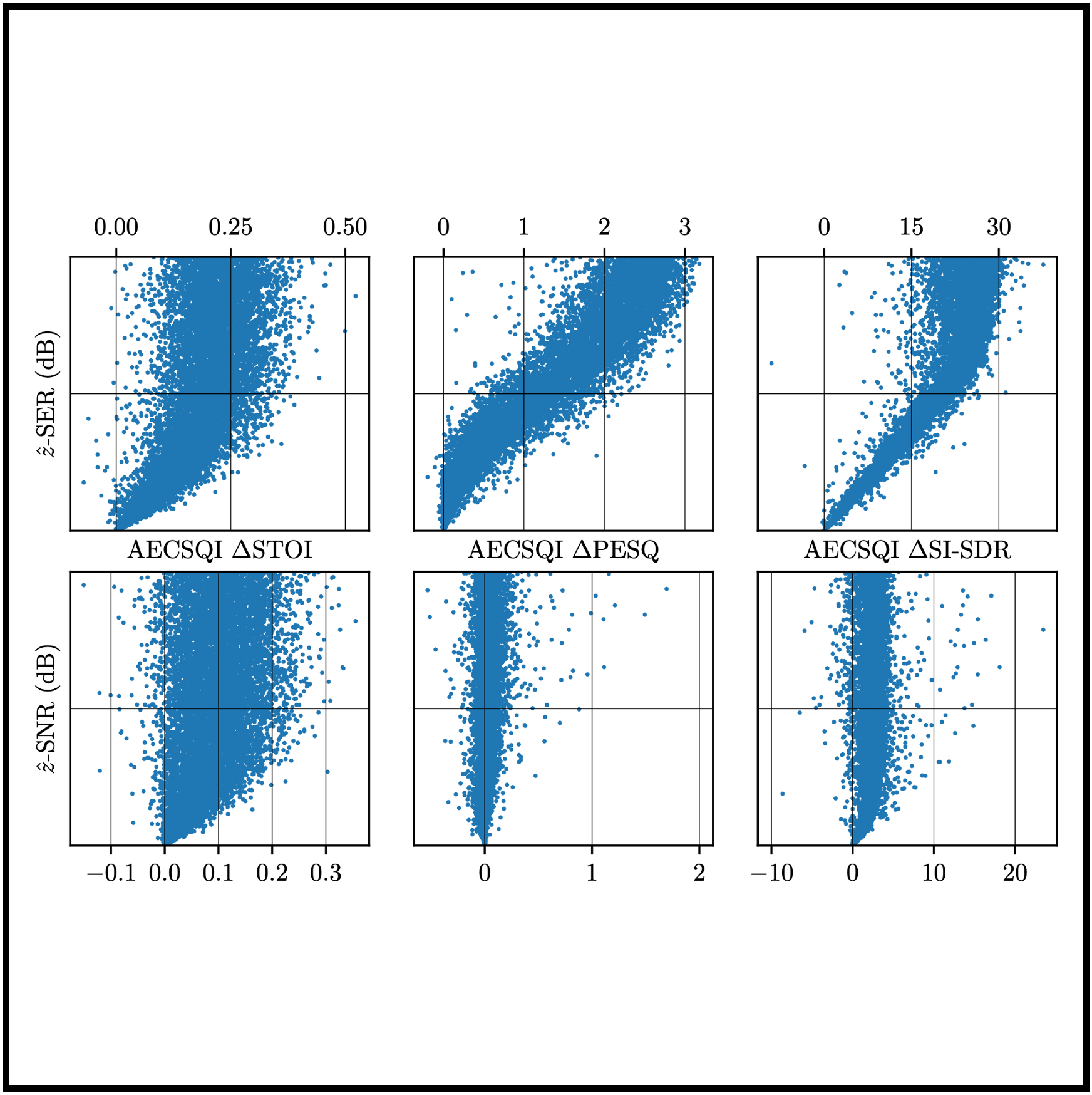 AECSQI: Referenceless Acoustic Echo Cancellation Measures using Speech Quality and Intelligibility Improvement
[TL;DR] [slides]
AECSQI: Referenceless Acoustic Echo Cancellation Measures using Speech Quality and Intelligibility Improvement
[TL;DR] [slides] Jin Woo Lee, Hyeong-Seok Choi, and Kyogu Lee IEEE WASPAA (Oral Presentation) 2023 |
| 11. |
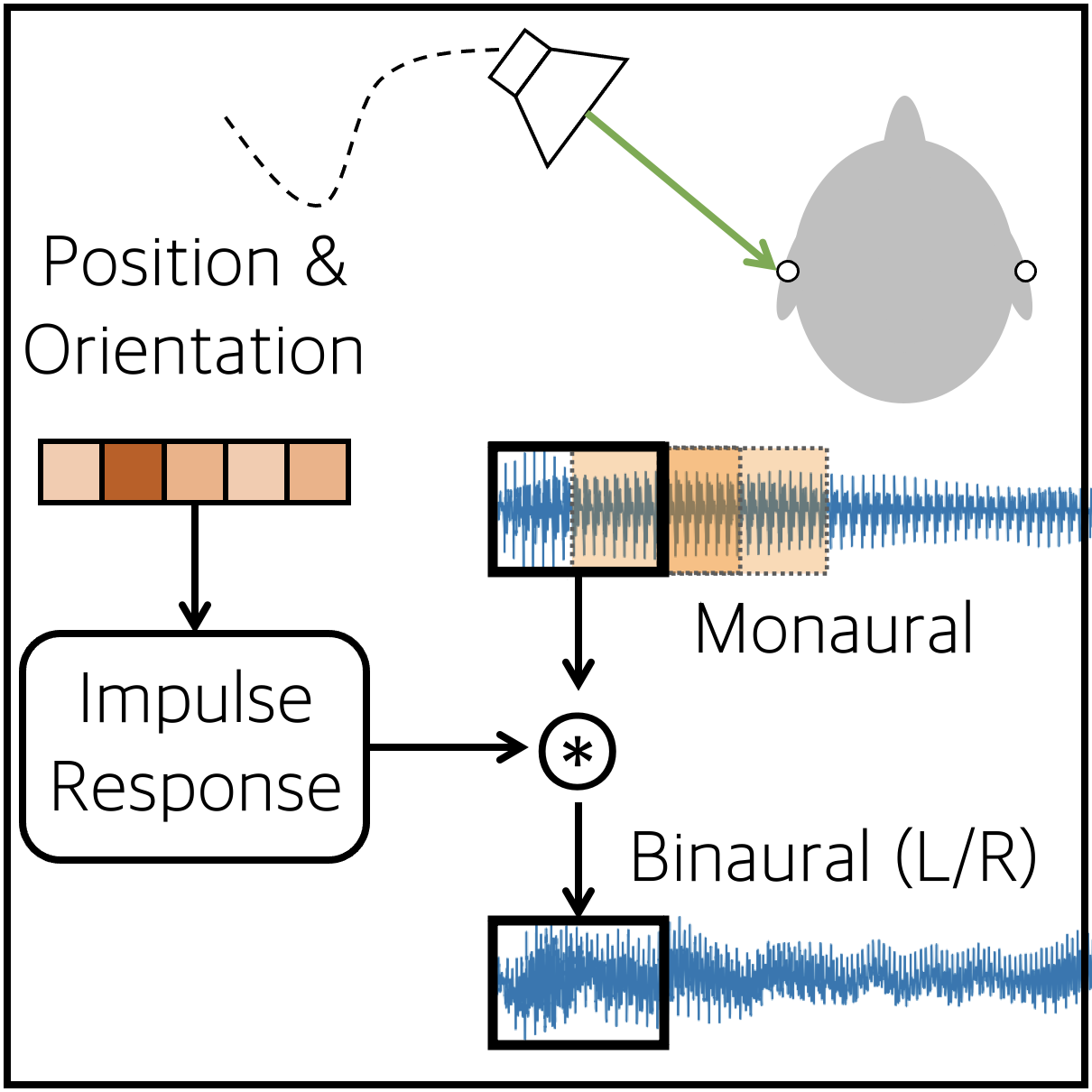 Neural Fourier Shift for Binaural Speech Rendering
[TL;DR] [code] [demo] [poster]
Neural Fourier Shift for Binaural Speech Rendering
[TL;DR] [code] [demo] [poster] Jin Woo Lee and Kyogu Lee IEEE ICASSP 2023 |
| 12. |
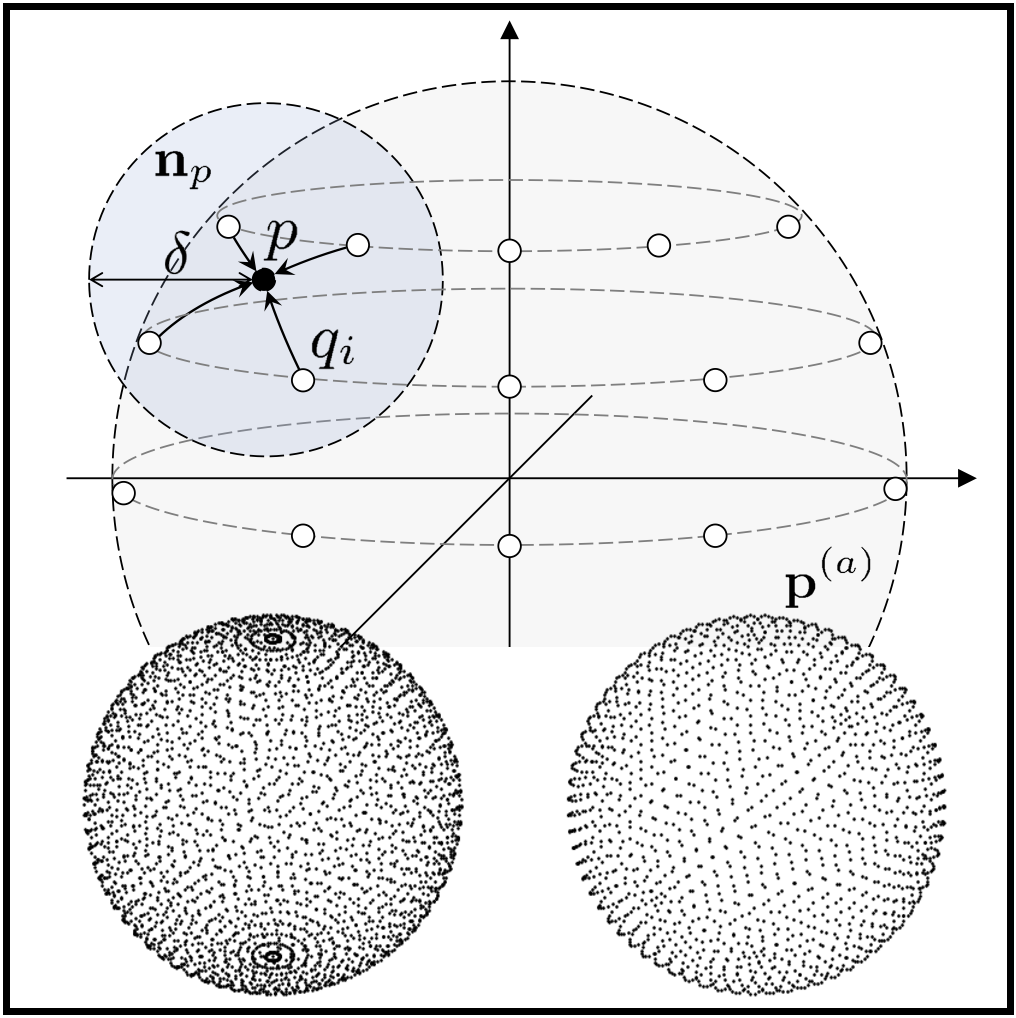 Global HRTF Interpolation via Learned Affine Transformation of Hyper-conditioned Features
[TL;DR] [code] [demo] [poster]
Global HRTF Interpolation via Learned Affine Transformation of Hyper-conditioned Features
[TL;DR] [code] [demo] [poster] Jin Woo Lee, Sungho Lee, and Kyogu Lee IEEE ICASSP 2023 |
| 13. |
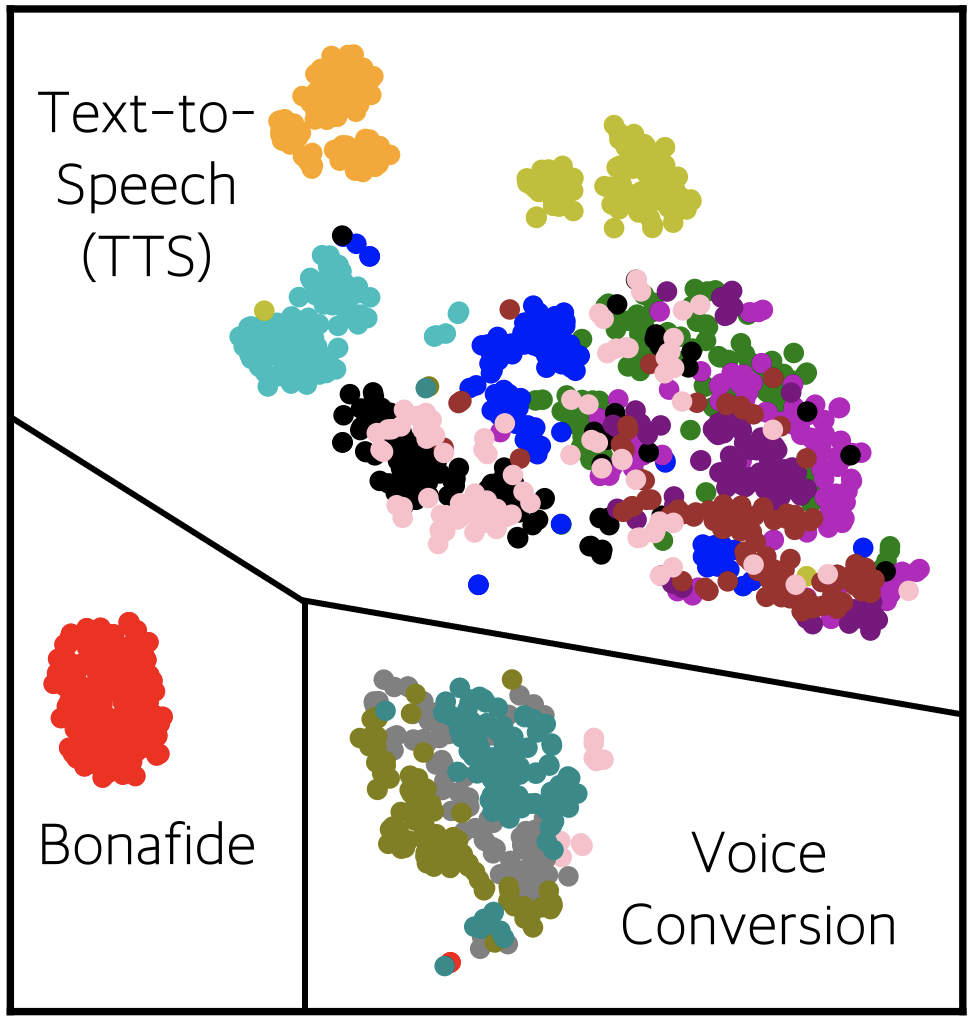 Representation Selective Self-distillation and wav2vec 2.0 Feature Exploration for Spoof-aware Speaker Verification
[TL;DR] [slides]
Representation Selective Self-distillation and wav2vec 2.0 Feature Exploration for Spoof-aware Speaker Verification
[TL;DR] [slides] Jin Woo Lee, Eungbeom Kim, Junghyun Koo, and Kyogu Lee ISCA Interspeech (Oral Presentation) 2022 |
| 14. |
 Deep Learning Approach in Multi-scale Prediction of Turbulent Mixing-layer
[TL;DR]
Deep Learning Approach in Multi-scale Prediction of Turbulent Mixing-layer
[TL;DR]Jin Woo Lee, Sangseung Lee, and Donghyun You arXiv 2019 |
| 1. | 2025 Differentiable Physical Modeling Sound Synthesis: Theory, Musical Application, and Programming, ISMIR 2025 Tutorial (presenters: Jin Woo Lee , Stefan Bilbao , Rodrigo Diaz ) |
| 1. | 2026 Physical Audio Simulation for Culture Technology and Musical Creativity, MIT, Music Tech Seminar |
| 2. | 2024 Differentiable Physical Modeling for Sound Synthesis: From Design to Inverse Problems, Stanford CCRMA, DSP Seminar |
| 3. | 2024 Differentiable Modal Synthesis for Physical Modeling of Planar String Sound and Motion Simulation, Korea Advanced Institute of Science & Technology (KAIST), Music and Audio Computing Lab |
| 4. | 2024 Physics-based Differentiable Sound Rendering and Machine Listening, University of Iowa, Dept. of Communication Sciences and Disorders, Professional Seminar |
| Topics in Music Technology: Physics-based Musical Instrument Design (KAIST, Instructor) | 2027S |
| Topics in Digital Heritage: Numerical Methods for Digital Reconstruction (KAIST, Instructor) | 2026F |
| Machine Listening (SNU, TA) | 2024F |
| Physical Modeling and Numerical Sound Synthesis (SNU, Student Instructor) | 2024S |
| Research Mentoring Certificate (RMC), MIT | 2026 |
| Kaufman Teaching Certificate Program (KTCP), MIT | 2025 |
Last updated on 2026-07-28