As another music generation model and physics-informed neural network specialized for the downstream task of understanding mechanics, I have learned and am still learning from various explorations and exploitations in my life. Here are a few replays from my memory related to this. I hope you enjoy!
One of the most exciting parts in doing music technology researches comes from making demos where we can deploy models for services and try out some nerdy examples. Sometimes, this can even be a motivation for a new research. My motivation for an immersive audio rendering came up similarly.
While it is an essence for the binaural audio technology to render the spatial perception to the audio, I wanted to render it in a more efficient manner. While there are many binaural audio rendering models, I’ve been working to reduce in the number of parameters and operations showing on-par performance to the baseline models in terms of perceptual spatiality. At the end of the day, what’s important for binaural technology is efficient enough performance to enable real-time behavior. Similar to learning an acoustic field, I designed the neural net to adapt its magnitude and phase response based on the source’s location and orientation. Here are some binaural samples rendered by my model.
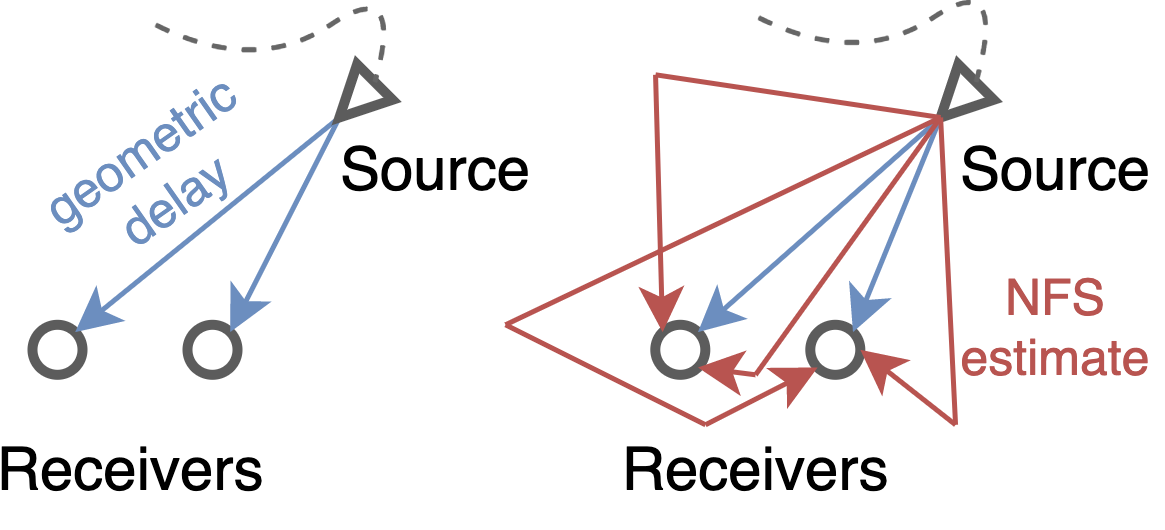
Visualization of the proposed idea
Bill Evans & Jim Hall - I Hear a Rhapsody
BTS - Dynamite
Jacob Collier - You and I
In particular, the music of Jacob Collier (who does a lot of things in terms of music technology) was rendered by imagining Jacob’s voice flying around in binaural audio. I remember the 12-note vocal harmonizer that Jacob showed at his performance at MIT and imagined that my technology could be used one day.
It could be binaural-rendered version of Jacob’s voice, but it could also be something else more creative — for example, what if we harmonize to 12-note with 12 different singers’ voices? Let me introduce another work that I’ve done on this topic as well.
During my internship at Supertone, I worked on singing vocal conversion. It takes input from two different singers and aims to convert the voice of one into the voice of the other, with the important condition that this must be done in real-time. Below are samples of the converted voice using the neural network.
Source input (male) — streamed online
Target query (female) — preprocessed and saved offline
Voice converted output (female) — streamed online
Of course, what I’ve done so far is one-to-one singer (voice) conversion, so I’ll have to make progress before we can change Jacob’s voice to 12 different people. But at the very least, it’s great to see that the concept works.

Excerpt from Kyodo News press release

Supertone board directors and me (photo credit: The JoongAng)

Me working at Supertone (photo credit: AI Times)
During the internship, I was fortunate to be appeared in the press (AI Times, Kyodo News, The JoongAng, …). I joined Supertone right before they received a big investment. (Coincidentally, the two periods I interned at Supertone, January 2021 and January 2023, overlaps exactly with the two periods HYBE invested in Supertone.) Back in the days before the acquisition by HYBE, when I started my internship, Supertone was a small start-up company with just one office room, but with incredibly enthusiastic and collaborative people.
Although I was just an intern, but watching the board of directors meet every day to run and grow the company gave me first-hand experience of what it takes to make a research-driven organization successful. It is pretty clear that this experience has been priceless. This has been an invaluable foundation for me in my leadership of the research group.
I also have a short history of building teams and leading them to success. I’ve also served as a project manager on a few research projects, taking them from proposal to contract closeout, but it’s the academic achievements that mean the most to me.
My undergraduate degree is in Mechanical Engineering, where I studied Computational Fluid Dynamics (CFD) intensely at the time. So even during my graduate studies in music and audio, I was interested in sound and the mechanisms by which sound waves propagate. It is similar to CFD in that it computes the dynamics of physical quantities in a discrete space-time approximating the governing equations. However, my graduate school was more of an interdisciplinary program and was more of an electronics and electrical engineering department, and it was hard to get a course in computer simulation of music and acoustics at my school.
So I took the initiative to gather colleagues to study physical modeling and numerical sound synthesis. Everyone was learning this stuff for the first time, including me, but our study group was able to successfully self-supervise and learn the material. As an achievement, I recently researched on implementing a physical modeling simulation engine for nonlinear string sound synthesis that runs flexible on CPUs and GPUs.
As a side note, I’m keenly interested in this kind of physical modeling and its AI-based improvements — for musical instruments, speech, and room acoustics simulation — and I’m still working on it. Feel free to contact me if you’re interested in collaborating!
Leaving aside the research-side novelties: Why is this physical modeling important for sound creation, especially nowadays when we have a world full of AI-based music generation models? Of course, diffusion- or Transformer-based generation models are undeniably great ways to generate music! And maybe, they can be way better if you’re not interested in a single instrument, but in multitrack/mixture generation. My point of view in doing physical modeling is that if we define a physical model, we’re fixing the mechanism by which music or sound propagates, and we’re interested in using that as a good inductive bias to do something else. The advantages can be many: robustness, interpretability, controllability, etc. But most of all, the idea of taking physical properties as input is appealing to anyone doing science, design, or manufacturing things.



I designed and manufactured an electric guitar during a visit to the Korea National University of Arts (KNUA). Stainless steel plates were cut and bent, then spot welded together to create the full-hollow stainless body.
The intent of designing a full hollow body in stainless steel stems from a question I had at the time of designing — how much do the physical properties of the body affect the tone of the electric guitar? Keeping in line with the telecaster’s characteristic shape, the guitar strings run through the body and are anchored to the back.
Although the body is completely full hollow, it weighs quite a bit since it is made of a steel. I’m pretty sure it’s heavier than a Les Paul, but it could slightly be more reverberant, especially since the strings run through the hollow body to the back of the guitar. In a usual electric guitar, the strings would go through a solid-wood body and connect to a spring-mounted backplate at the back (which creates a little bit of nice reverb). And in an acoustic guitar, the strings would connect to a bridge at the top. It also differs from a typical resonator guitar in that it has magnetic pickups without resonators. In this guitar, since the top and back are both resonating, creating a bit of reverb, so it could be said that the entire empty body is working as as a ‘backplate’. In order for the hollowed body to support the tension of the string, sound posts are installed inside the body.

Laser-cut stainless steel plates before welding.

Polishing the body after welding

The bridge finally mounted after all the troubles.
Stainless steel plates were cut and bent, then welded together to create the full hollow stainless tin guitar body. The body shape was adopted from Fender Telecaster. The stainless steel plate that forms the top of the body was cut to install the guitar parts, including the pick guard, volume knob, and bridge, I connected the circuit for each part and install the strings.
Me playing the tin guitar I made.
Can you hear the difference in sound compared to a canonical telecaster? How is it different? It would be nice to play the same thing on a different guitar, but unfortunately, I can’t repeat the same performance on a different guitar, mainly due to my inherent stochasticity. The answer to that question above is, well, we’ll get to know when music technology advances!
I’ve conducted research aimed at improving the acoustic characteristics of speakers using dielectric elastomers. To achieve this, I designed a physics-based model to simulate the effects of variations in the input signal to the dielectric elastomer. more specifically, I’ve represented the deformation of the thin-film elastomer in response to its electrical signal as a nonlinear ODE. When a high-voltage is applied between the sandwiched electrodes, Maxwell stress is applied to the elastomer, which deforms in (visco-)hyperelastic manner. Based on this model, I proposed methods to enhance acoustic characteristics (nonlinear distortion).
Dielectric elastomer actuator array with single-pixel control

Dielectric elastomer actuator array mounted in deformable cavities
To demonstrate the effectiveness of the proposed model in reducing distortion, I measured the deformation and the resulting sound produced by fabricated and operated elastic speakers using sensors like microphones and LDVs. The proposed model was successfully validated by showing its capability to reduce distortion in the measured sound. The findings related to this research have been submitted to the journal ‘Applied Mathematical Modelling’. Above pictures are two types of the experimented thin-film speakers, in an array structure. LHS is also equipped with photonic nanocrystal gel that changes its color according to its strain (so it visualizes the amount of the elastomer’s stretch).
My passion for research on music technology began as an undergraduate student. In 2014, at the age of 20, I helped working on a paper titled “Globalization Strategy of Korean Traditional Music - A Case Study of Hybrid Rock Band Jambinai,” which was a case study of a Korean post-rock band ‘Jambinai’ who uses traditional Korean folk music instruments. Interviewing the band, I analyzed how they adapted traditional instruments to rock music.
As the paper was nearing completion, I was drafted into the mandatory military service, so I didn’t get to be an author and ended up being mentioned in the acknowledgments, but this was truly my first research experience doing a case study with my own hands.
In the military, I worked as a mechanic in Republic of Korea Army Aviation Operations Command. I was mainly responsible for maintaining UH-60 helicopters (Sikorsky Aircraft), also known as “Black Hawk”. I served as a mechanic and crew chief as a sergeant. To this end, I completed the Army Aviation School, received basic training in helicopter maintenance, and received qualification. While in the military, I learned basic maintenance knowledge and the basics of aerodynamics, but it also gave me the opportunity to think deeply about acoustics, such as the rotor noise of helicopters and communication equipment.

Me (center) and my crew during an operation at Yeonpyeong Island
I served as a crew chief on the Chairman of the Joint Chiefs of Staff’s airborne operations for about eight months. I served with General Sun-jin Lee when he was Chairman of the Joint Chiefs of Staff, and I spent more than 300 hours in helicopters traveling around the country. We went to the DMZ and Pohang, and there’s a video footage of our visit to Yeonpyeong Island. I also have worked as a Military Interpreter during the Ulchi-Freedom Guardian in 2016.
I’ve been a fan of music for a long time. Not just playing, but composing, mixing and mastering music, and building new instruments. My love for music probably started when I was in school, loving rock music and playing guitar in a band.

Me rehearsing before a show

That pillar of fire got on my nerves, obviously.
The more I perform, the more I realize that the main impact a band has on me is something other than looking good on stage. In fact, the process of preparing the performance is more enjoyable for me — after all, to perform well on stage, you need to accomplish it by finishing the project within the given deadline.
Forming a band and putting together a setlist for a show takes a lot of collaboration and leadership. It also requires patience and high standards that should not be easily met, as I must keep on practicing my instruments (and there’s never enough practice). In addition, peer review is done by listening to each other’s performances and giving feedback, and self-objectification is cultivated by accepting feedback from others. Perhaps these factors are what make me love playing in a band so much.


We sometimes record when we’re happy with what we’re getting out of the band, whether it’s a cover of a favorite song or something we’ve written ourselves. Here are some songs that I’ve had a hand in writing, and have been released: [1, 2].
